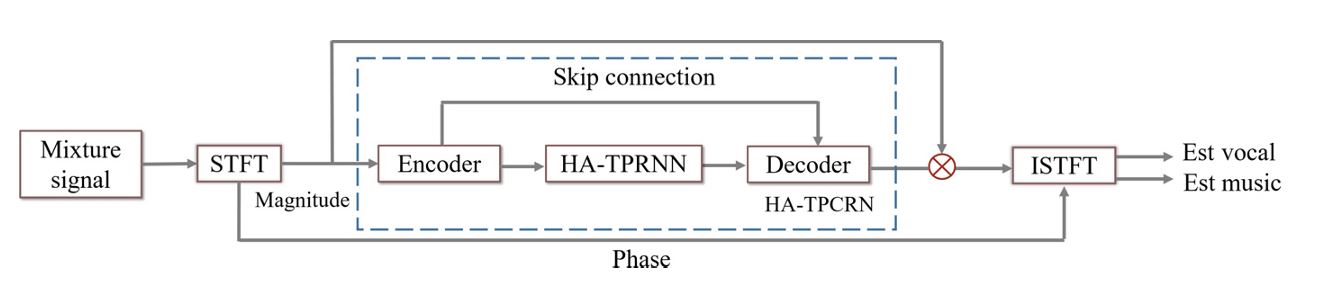
Temporal coherence and spectral regularity are critical cues for human auditory streaming processes and are considered in many sound separation models. Some examples include the Conv-tasnet model, which focuses on temporal coherence using short length kernels to analyze sound, and the dual-path convolution recurrent network (DPCRN) model, which uses two recurring neural networks to analyze general patterns along the temporal and spectral dimensions on a spectrogram. By expanding DPCRN, a harmonic-aware tri-path convolution recurrent network model via the addition of an inter-band RNN is proposed. Evaluation results on public datasets show that this addition can further boost the separation performances of DPCRN.